
Architecture and Design of Subversion - SVN (Part 2)

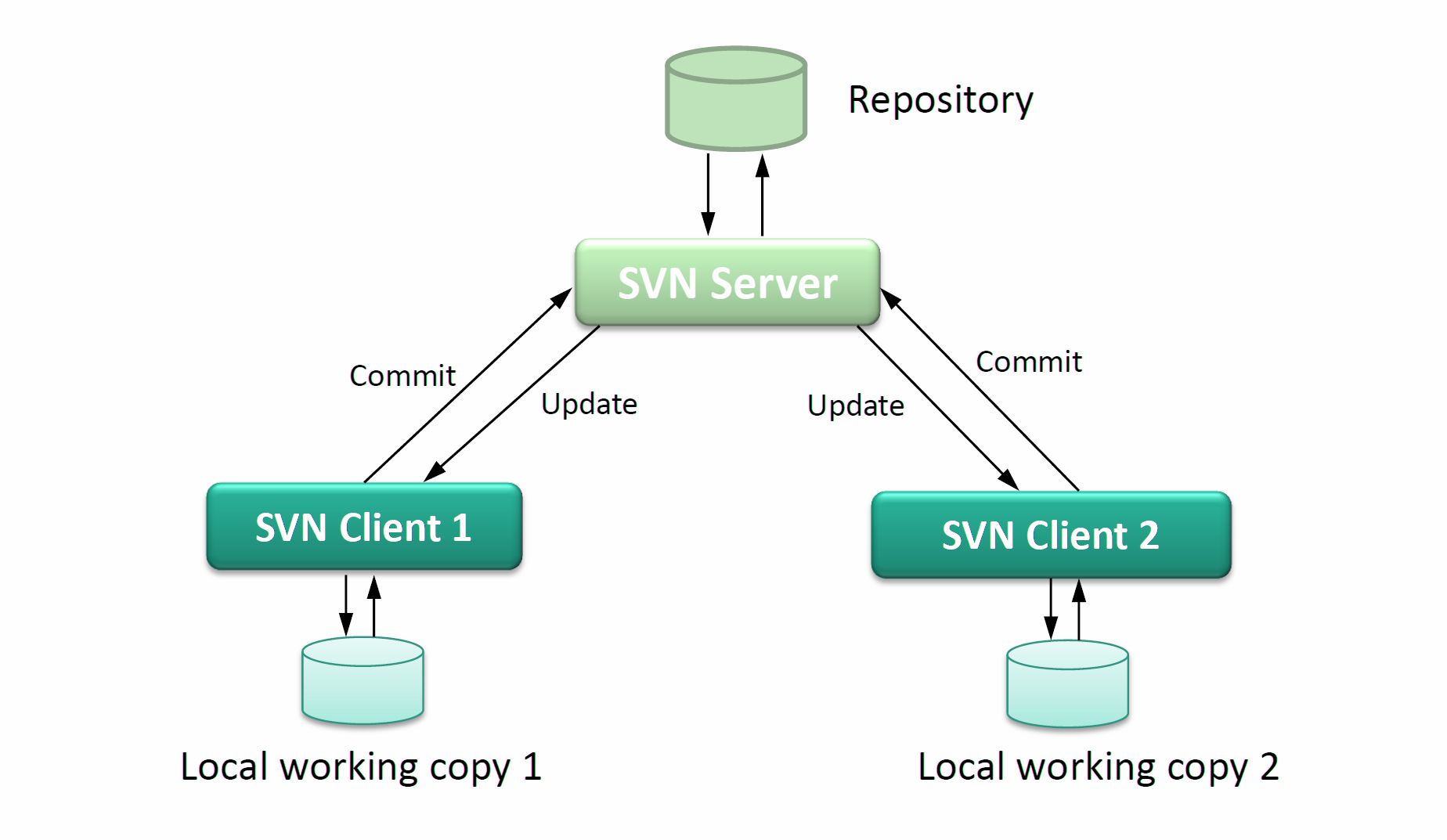
In part 1, we had learnt about architecture and design of SVN, as well as some definitions, actions and tools for SVN. In this part, we will go deeply about SVN designing concept as well as some advanced terms in using SVN. Finally, we will give you some good tips and tricks to use in SVN environment.
First, say hello to an older system, called CVS.
CVS
CVS uses normal client – server connection, while Linux-based server acts like datastore of version control, all clients will connect to server through network to perform actions, like checkout, checkin and update.
CVS supports delta-compression as well as branching for project, however it has some disadvantages:
- revision is increased by every single file
- poor support for Unicode and other encodings
- does not support versioning for renamed/removed file
- commit is not atomic action
- costly branch operations
- all files are treated as text
CVS development is stopped in 2011 and no new features are added furthermore.
SVN Features
SVN has many powerful features when comparing to CVS:
- directory versioning
- store all history of all items
- commit is an atomic operation
- support item metadata, which work like item itself
- support for SSH
- use binary comparing algorithm which operates independently in text/binary files
- effectively process branch and tag
- writen in C, own fully API libraries for support multiple languages and platforms
SVN Package
SVN contains primary tools, including:
- svn: CLI of SVN
- svnversion: working copy reporter
- svnlook: use for searching and filtering inside reposirory
- svnadmin: create and modify repository
- svnserve: module for Apache to run SVN server
Versioning Solution
When it comes to design a version control system, there is a core problem need to be resolved: support for sharing data between user without overwrite anything. This situation is described as follow:
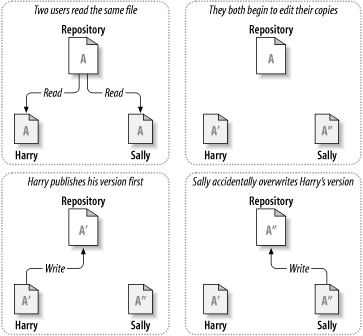
- First, Harry and Sally read file A from repository
- They both edits this file
- Harry finishes his first, then publish A’ to repository
- Later, Sally is done and, publish A” to repository
Result: resository now contains only A”, which is copy from Sally and lost the copy from Harry, which is A’. This issue can be resolved by Lock-Modify-Unlock method:
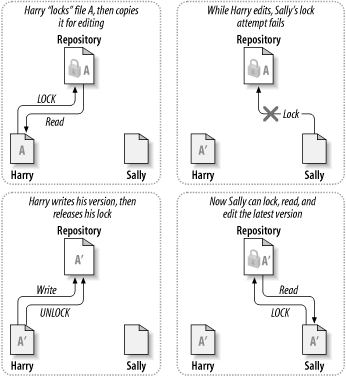
- Harry reads file, repository will lock file A
- Sally tries to read file A and will be rejected due to it has already been locked
- Harry finishes with file A, write to repository and release lock
- Now Sally can acquire lock, read file and do needed modification
This method has big disadvantages:
- Administrator permission: when Harry locks file, no one else can access this file which lead to time wasting
- Different users can not edit the same file though they want to edit in different parts
- Different files if are independently locked, will break data integrity if they are depend on others
Another method can solve those issues called Copy-Modify-Merge
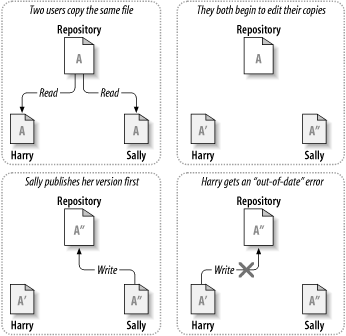
- First, Harry and Sally read file A from repository
- They edit this file in parallel
- Sally finishes first, write A” to repository
- After that, Harry finishes, tries to write A’ to repository and will face out-of-date error
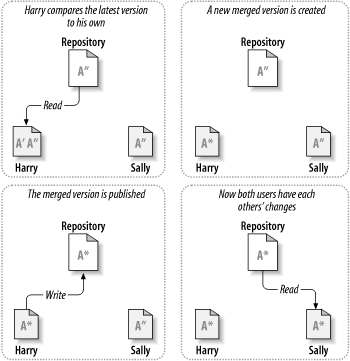
- Now Harry reads file A from repository again
- Harry compares and manually merges changes from A” to his A’ to create A* version
- Harry writes A* to repository
- Sally reads A* from repository
- Now Harry, Sally and repository all contains A* with necessary changes from both Harry and Sally
This method still has a case which merging can has error, it is when Harry and Sally are trying to modify the same code or function which system can not perform auto-merging. This is what we called conflict in previous post.
Modern version control systems have auto-merge features, however when conflicts are occured, users should review and fix manually.
Revision
SVN tracks items by their revision, and all working copy only has one common revision number. Only modified file in a commit can have this commit’s revision, other files which are not modified will own old revision number.
Because SVN stores history of all files, thus we will never lose any information even if we delete file, rename of break something. We can always revert a file to a specific revision to get content of that file.
When we use SVN with branch and tag, we should have situations which we need to merge, switch or perform log and diff. You should go on real project to get more knowledge and you will find out those are easy too.
Tips & Tricks
Below are some tips and tricks of me, when directly working with SVN:
- we should use default structure
branches/tags/trunkwhen creating SVN - apply same structures for each project, if SVN repository contains many projects
- do not commit anything related to local properties and settings, should ignore them instead
- do not commit anything which can be created by build/make process, should ignore them instead
- do not commit anything which can be created from an item which exists inside repository
/bin,/gen, etc. are directories which should ignored at first time- only one guy should be responsible for creating/managing branch/tag to ensure SVN structure is correctly maintained
- some good free SVN provider: Google Code, Assembla